Written by
LSM
on
on
nlp:추천 알고리즘
추천 알고리즘
- 아마존, 넷플릭스와 같은 행위 데이터를 분석한 맞춤형 데이터 추천
- 뉴스 글 등의 내용을 분석하여 유사도 계산을 통해 추천하는 것
Collaborative Filtering
- 사용자들로부터 얻은 기호 정보를 바탕으로 사용자들의 관심을 자동적으로 예측해주는 방법
- 사용자들의 과거 경험이 미래에도 이어질 것이라는 전제가 깔려 있음
User based Collaborative Filtering
- 사용자 간의 유사도를 비교해 다른 사용자에게 리스트를 추천해주는 알고리즘
- 행렬을 이용해 사용자 간의 유사도를 비교
- 데이터가 별로 없는 신규 사용자에 대해서는 정확도가 떨어짐
- 피어슨 상관계수를 이용해 유사도를 비교
-
메모리 기반의 알고리즘
- 장점
- 아이템 자체 데이터가 없어도 구축 가능
- 구축 간단
- 단점
- 사용자-아이템 양이 많아질 수록 연산이 복잡해지고 자원 소모가 많아짐
- 신규 사용자는 데이터가 없어 사용자 간 유사도를 구할 수 없음
피어슨 상관 계수
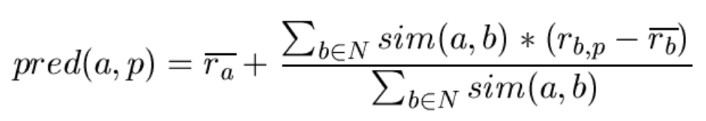
- 유사도 계산을 위해 많이 사용되는 식
- 비교 대상의 두 변수의 선형적인 관계를 추정
- 값이 동일 방향으로 움직였는가
- 비례 관계
- 반비례 관계
- 관계를 추정할 수 없는가
- 값이 동일 방향으로 움직였는가
- 유사도에 따른 다른 사용자의 값을 이용해 가중치를 조절함
Item based Collaborative Filtering
- 아이템 간의 유사도를 비교해 아이템 리스트를 추천해주는 알고리즘
- 코사인 유사도를 이용해 유사도를 비교
-
메모리 기반의 알고리즘
- 장점
- 구현이 쉬움 및 이해가 간단
- 머신러닝과 같은 최적화 과정이 불필요하고 수식 변경을 통해 고칠 수 있음
- 단점
- 정보가 적을 경우 정확도가 높지 않음
- 아이템이 많을 경우 계산 시간이 오래 걸림
코사인 유사도
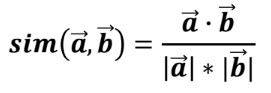
- 평점을 벡터로 생각
- 2개의 벡터 사이를 계산해 각도가 작을수록 가까이에 위치해 비슷하다고 판단
Model based Methods
- 머신러닝을 이용해 평점을 예측할 수 있는 시스템을 만듦
- 과거 사용자 평점 정보를 이용해 모델을 만들기 때문에 정보가 없는 아이템에 대해 사용자 평점을 예측할 수 있음
Model 만드는 방법
- Matrix Factorization
- SVD
- PCA
- Association Rule Mining
- Shopping Basket Mining
- Probabilistic Model
- Clustering
- Bayesian Networks
- ETC
- Regression
- SVM
- Decision Tree etc….
Reference
- https://proinlab.com/archives/2103
- https://ko.wikipedia.org/wiki/%ED%98%91%EC%97%85_%ED%95%84%ED%84%B0%EB%A7%81
- https://www.oss.kr/info_techtip/show/5419f4f9-12a1-4866-a713-6c07fd36e647